
Linear Regression Assumptions
There are four assumptions fundamental to linear regression:
- Linearity: The relationship between x and the mean of y is linear.
- Homoscedasticity: The variance of residual is the same for any value of x (i.e, constant variance).
- Independence: Independence of the prediction error from every one of the predictor variables.
- Normality: The prediction error is normally distributed.
When conducting linear regression, we need to always perform diagnostic check to ensure we are not violating any of the inherent assumptions.
Linearity
| The assumption is that the relationship between x and the mean of y is linear, but what does that mean exactly? A regression model is linear if $E[Y | X =x]$ is a linear function of the $\beta$ parameters, not of $x$. That means each of the following is a linear model: |
- $\beta_{0} + \beta_{1}x$ (note^[This model is linear in $\beta$ and $x$])
- $\beta_{0} + \beta_{1}x + \beta_{2}x^{2} + \beta_{3}x^{3}$
- $\beta_{0} + \beta_{1}log(x) + \beta_{2}sin(x)$
These are not linear models:
- $\beta_{0} + x^{\beta_{1}}$
- $\frac{1}{\beta_{0} + \beta_{1}x}$
- $\frac{e^{\beta_{0}+\beta_{1}x_{1}}}{1+e^{\beta_{0}+\beta_{1}x_{1}}}$ (note^[This is actually logistic regression, which is covered later.])
As with ANOVA, R produces diagnostic plots for objects created by the lm() function. The first plot may be used to evaluate both linearity and homoscedasticity. A linear relationship will be indicated by a (relatively) horizontal red line on the plot. Since our height-weight data is so simple, we’ll switch to the teengamb dataset from the faraway package. This dataset consists of four predictor variables and one response (gamble). Read the help for teengamb to familiarize yourself with the data. Since one of the predictors is binary (sex), we’ll exclude it for this example. ^[The variable was excluded for simplicity at this point, not because we can’t include binary predictors in a linear model. We’ll cover this in a later section.] A summary of the resulting linear model is as follows.
library(tidyverse)
library(faraway)
tg.lm = lm(gamble ~ . -sex, data=teengamb)
summary(tg.lm)
##
## Call:
## lm(formula = gamble ~ . - sex, data = teengamb)
##
## Residuals:
## Min 1Q Median 3Q Max
## -49.649 -12.008 -1.242 8.239 103.390
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.3044 15.7760 -0.083 0.9345
## status 0.4701 0.2509 1.873 0.0678 .
## income 5.7707 1.0494 5.499 1.95e-06 ***
## verbal -4.1211 2.2785 -1.809 0.0775 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 24.28 on 43 degrees of freedom
## Multiple R-squared: 0.445, Adjusted R-squared: 0.4062
## F-statistic: 11.49 on 3 and 43 DF, p-value: 1.161e-05
The diagnostic plot to check the linearity assumption is the first plot returned, and we see a slight “U” shape to the red line. Notice that there are only three observations on the far right which appear to be heavily influencing the results. The conical spread of the data also strongly suggests heteroscedasticity might be an issue.
plot(tg.lm, which = 1)

Another screening method is with a pairs plot, which we can quickly produce in base R with pairs(). This is a great way to do a quick check potential nonlinear relationships between pairs of variables. This is a screening method only, however, because we’re projecting onto two dimensions, so we may be missing things lurking in higher dimensions.
pairs(teengamb[, 2:5], upper.panel=NULL, lower.panel=panel.smooth)

If evidence of a nonlinear relationship exists, a linear model can still be used; however, either the response variable or one or more of the predictors must be transformed. This topic is covered in detail in the Advanced Designs chapter.
Homoscedasticity
The procedure for testing constant variance in residuals in a linear model is similar to ANOVA. A plot of residuals versus fitted values is shown two plots ago, and we can look at the square root of standardized residuals versus fitted values. Both plots show strong evidence of heteroscedasticity.
plot(tg.lm, which = 3)

There is no doubt some subjectivity to visual inspections. As a guide, consider the next three sets of plots that show constant variance, mild heteroscedasticity, and strong heteroscedasticity.
Constant variance:
par(mfrow = c(3,3), oma = c(5,4,0,0) + 0.1, mar = c(0,0,1,1) + 0.1)
n <- 50
for(i in 1:9) {x <- runif(n); plot(x,rnorm(n))}

Mild heteroscedasticity:
par(mfrow = c(3,3), oma = c(5,4,0,0) + 0.1, mar = c(0,0,1,1) + 0.1)
for(i in 1:9) {x <- runif(n); plot(x,sqrt((x))*rnorm(n))}
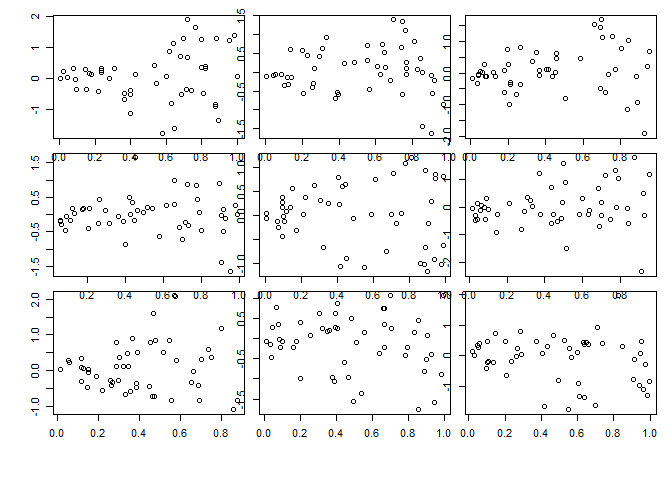
Strong heteroscedasticity:
par(mfrow = c(3,3), oma = c(5,4,0,0) + 0.1, mar = c(0,0,1,1) + 0.1)
for(i in 1:9) {x <- runif(n); plot(x,x*rnorm(n))}

The linear model analog to the Levene test is the Breusch-Pagan test. The null hypothesis is that the residuals have constant variance, and the alternative is that the error variance changes with the level of the response or with a linear combination of predictors. The ncvTest() from the car (companion to applied regression) package performs the test, and when applied to the tg.lm object confirms our suspicion of non-constant variance based on our visual inspection.
car::ncvTest(tg.lm)
## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 26.18623, Df = 1, p = 3.1003e-07
Independence
The concept of independent (and identically distributed) data was covered in the statistics review and ANOVA chapters. It is no different when conducting linear regression and so will not be repeated here.
Normality
Again, checking whether the residuals are normally distributed is the same for linear regression as for ANOVA. Create a Q-Q plot and apply the Shapiro-Wilk test as shown below.
plot(tg.lm, which=2)
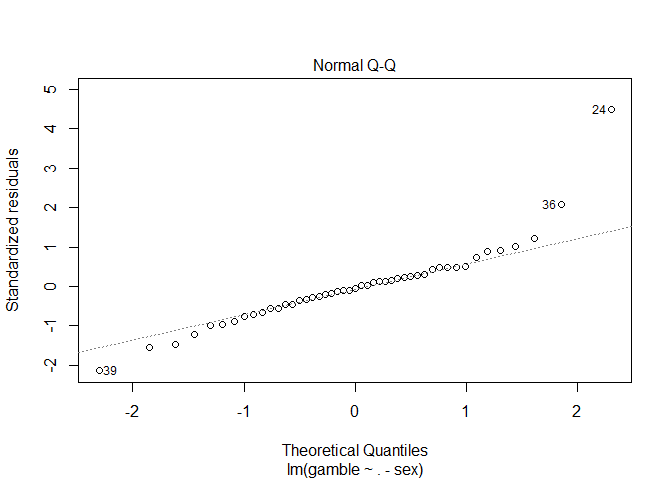
shapiro.test(residuals(tg.lm))
##
## Shapiro-Wilk normality test
##
## data: residuals(tg.lm)
## W = 0.8651, p-value = 6.604e-05
Unusual Observations
Although not an assumption inherent to a linear model, it’s good practice to also check for unusual observations when performing diagnostic checks. There are two types of unusual observations: outliers and influential. An outlier is an observation with a large residual - it plots substantially above or below the regression line. An influential observation is one that substantially changes the model fit. Keep in mind that it is possible for an observation to have both characteristics. Examples Both types of observations are shown on the following plot (note that I rigged observations 11 and 12 to be unusual observations).
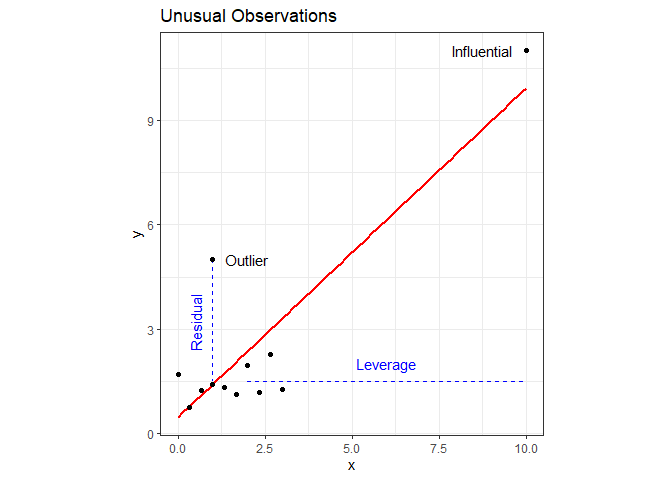
It’s not necessarily bad to have unusual observations, but it’s good practice to check for them, and, if found, decide what to do about them. A point with high leverage falls within the predictor space but is significantly separated from the other points. It has the potential to influence the fit but may not actually do so.
Leverage Points
The amount of leverage associated with each observation is called the hat value and are the diagonal elements of the hat matrix, which you can read more about here, if you’re interested (or just really like linear algebra). The gist of it is that the sum of the hat values equals the number of observations. If every observation has exactly the same leverage, then the hat values will all equal $p/n$, where p is the number of parameters and n is the number of observations (in our example we just have two parameters, so it’s $2/n$). Increasing the hat value of one observation necessitates decreasing the hat values of the others, so we’re essentially looking for hat values significantly greater than this theoretical average. The generally accepted rule of thumb is that hat values greater than ~ $2p/n$ times the averages should be looked at more carefully. Extracting hat values from a linear model in R is done using the hatvalues() or influence() functions.
df.lm = lm(y~x, data=df)
hatv = hatvalues(df.lm)
print(hatv)
## 1 2 3 4 5 6 7
## 0.14483261 0.12736536 0.11280932 0.10116448 0.09243086 0.08660844 0.08369723
## 8 9 10 11 12
## 0.08369723 0.08660844 0.09243086 0.10116448 0.88719068
influence(df.lm)$hat
## 1 2 3 4 5 6 7
## 0.14483261 0.12736536 0.11280932 0.10116448 0.09243086 0.08660844 0.08369723
## 8 9 10 11 12
## 0.08369723 0.08660844 0.09243086 0.10116448 0.88719068
Verify that the sum of the hat values equals the number of parameters (2):
print(paste("Sum of hat values:", sum(hatv)))
## [1] "Sum of hat values: 2"
Are any hat values > $2p/n$ (recall I rigged observation 12)?
hatv > 4/length(df$x)
## 1 2 3 4 5 6 7 8 9 10 11 12
## FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
A graphical way of looking at leverage is with the halfnorm() function in the faraway package, which plots leverage against the positive normal quantiles. I added a red line to indicate the rule of thumb threshold.
faraway::halfnorm(hatv,ylab="Leverages")
abline(h=2*mean(hatv), col='red')

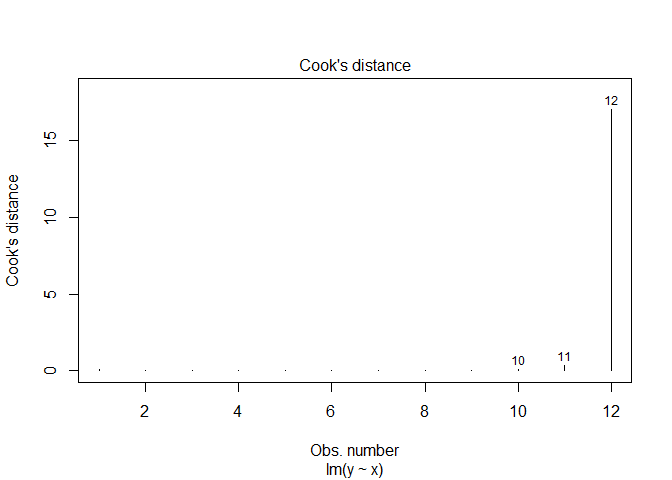
Another measure of leverage is Cook’s Distance, defined as:
\[D_{i}=\frac{r^{2}_{i}}{p}\left(\frac{h_{i}}{1-h_{i}}\right)\]The rule of thumb for Cook’s Distance is an observation with $D>1$, and we can get these values in R with cooks.distance().
cooks.distance(df.lm)
## 1 2 3 4 5 6
## 6.193970e-02 4.398193e-05 6.553697e-04 4.789149e-10 3.736810e-03 1.917568e-02
## 7 8 9 10 11 12
## 3.490432e-03 4.701066e-02 1.130421e-02 9.893220e-02 3.409595e-01 1.703556e+01
The fourth linear model plot also contains Cook’s Distance.
plot(df.lm, which=4)
Outliers
The hat values from the previous section are also used to calculate standardized residuals, $r_{i}$.
\[r_{i}=\frac{\hat{\varepsilon}_{i} }{\hat{\sigma}\sqrt{1-h_{i}}}, i=1,...,n\]| where $\hat{\varepsilon}$ are the residuals, $\hat{\sigma}$ is the estimated residual standard error, and $h$ is the leverage. The rule of thumb for identifying unusually large standardised residuals is if $ | r_{i} | > 2$. We can get standardized residuals in R with rstandard(). |
rstandard(df.lm)
## 1 2 3 4 5
## 8.552478e-01 -2.454950e-02 1.015300e-01 -9.225082e-05 -2.708924e-01
## 6 7 8 9 10
## -6.359731e-01 -2.764512e-01 -1.014559e+00 -4.882963e-01 -1.393847e+00
## 11 12
## 2.461458e+00 2.081408e+00
Here we see that observation 11 is a potential outlier, and the observation 12 is both a high leverage point and a potential outlier.
We can also look at studentized residuals, which are defined as:
\[t_{i} = r_{i}\sqrt{\frac{n-p-1}{n-p-r^{2}_{i}}}\]In R, we can use rstudent():
rstudent(df.lm)
## 1 2 3 4 5
## 8.427665e-01 -2.329041e-02 9.636946e-02 -8.751682e-05 -2.579393e-01
## 6 7 8 9 10
## -6.159215e-01 -2.632726e-01 -1.016216e+00 -4.688619e-01 -1.473142e+00
## 11 12
## 3.719616e+00 2.622850e+00
It may be useful to view all of these measures together and apply some conditional formatting.
library(kableExtra)
df %>%
mutate(
obs = 1:nrow(df),
r.standard = round(rstandard(df.lm), 3),
r.student = round(rstudent(df.lm), 3),
i.hatv = round(hatvalues(df.lm), 3),
i.cook = round(cooks.distance(df.lm), 3)) %>%
mutate(
r.standard = cell_spec(r.standard, "html", color=ifelse(abs(r.standard)>2,"red", "black")),
r.student = cell_spec(r.student, "html", color=ifelse(abs(r.student)>2,"red", "black")),
i.hatv = cell_spec(i.hatv, "html", color=ifelse(i.hatv>4/nrow(df),"red", "black")),
i.cook = cell_spec(i.cook, "html", color=ifelse(i.cook>1,"red", "black"))) %>%
kable(format = "html", escape = F) %>%
kable_styling("striped", full_width = F)
| x | y | obs | r.standard | r.student | i.hatv | i.cook |
|---|---|---|---|---|---|---|
| 0.0000000 | 1.6854792 | 1 | 0.855 | 0.843 | 0.145 | 0.062 |
| 0.3333333 | 0.7509842 | 2 | -0.025 | -0.023 | 0.127 | 0 |
| 0.6666667 | 1.2482309 | 3 | 0.102 | 0.096 | 0.113 | 0.001 |
| 1.0000000 | 1.4164313 | 4 | 0 | 0 | 0.101 | 0 |
| 1.3333333 | 1.3354675 | 5 | -0.271 | -0.258 | 0.092 | 0.004 |
| 1.6666667 | 1.1136044 | 6 | -0.636 | -0.616 | 0.087 | 0.019 |
| 2.0000000 | 1.9557610 | 7 | -0.276 | -0.263 | 0.084 | 0.003 |
| 2.3333333 | 1.1860038 | 8 | -1.015 | -1.016 | 0.084 | 0.047 |
| 2.6666667 | 2.2758785 | 9 | -0.488 | -0.469 | 0.087 | 0.011 |
| 3.0000000 | 1.2686430 | 10 | -1.394 | -1.473 | 0.092 | 0.099 |
| 1.0000000 | 5.0000000 | 11 | 2.461 | 3.72 | 0.101 | 0.341 |
| 10.0000000 | 11.0000000 | 12 | 2.081 | 2.623 | 0.887 | 17.036 |
What To Do About Unusual Observations
In the book, Linear Models With R, Faraway1 gives advice on this topic that I’ll paraphrase.
- Check for data entry errors and correct any that are found.
- Consider the context. An unusual observation may be the single most important observation in the study.
- Exclude the observation from the dataset and refit a model. If it makes little to no difference in your analysis, then it’s usually best to leave it in.
- Do not automate the process of excluding outliers (see #2 above).
- If you exclude an observation, document it in your report and explain your rationale so that your analytic integrity is not questioned.
-
Faraway, Julian. 2014. “Linear Models With R.” Chapman & Hall. ↩




Comments