
PyTorch DQN Solves LunarLander-v2
Why PyTorch?
A couple of weeks ago, I attempted to install the GPU version of TensorFlow and failed miserably. I should have set up a new virtual environment for it, but threw caution into the wind and installed it in my base environment. Bad idea. As a result, when I import the TensorFlow module, I get pages and pages of error messages. I spent an entire morning Googling for solutions, and eventually gave up. So, I decided to see if I would have any better luck with PyTorch. Within minutes, I was up and running on my GPU - nice! What follows is me just working out how to implement a deep Q-network (DQN) in PyTorch. I’m not going to re-hash how DQN’s work since I already covered that ground in a previous post. I also found a better way to render the environments in a Jupyter notebook using HTML from from IPython.display.
import gym
from gym import wrappers
import random
import torch
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
import io
import base64
from IPython.display import HTML
%matplotlib inline
Lunar Lander Environment
The state of a Lunar Lander environment has eight continuous values that represent the lander’s x and y position, it’s velocity, angular speed, orientation, and other. With DQN, it doesn’t really matter what they all are, I just need to know how many there are. There are also four discrete actions: do nothing, fire left rocket, fire right rocket, and fire the main rocket. The reward system is more complicated, too. A small negative reward of -0.3 is given for each time the rocket is fired, and a large negative reward (-100) if the lander crashes. If the lander comes to rest on the ground, a positive reward of 100 is given, and a reward between 100-140 is given depending on how close to the center of the pad (marked by two flags) it lands.
env = gym.make('LunarLander-v2')
env.seed(0)
print('State shape: ', env.observation_space.shape)
print('Number of actions: ', env.action_space.n)
State shape: (8,)
Number of actions: 4
The PyTorch Model
I set up a neural net with three hidden layers and 128 nodes each with a 60% dropout between each layer. The net also uses the relu activation function. All of this is in a separate file model.py, which I import in another script dqn_agent.py. The agent script sets up the replay buffer, epsilon greedy policy, the training hyperparameters, etc. as I described in previous posts.
import torch
import torch.nn as nn
import torch.nn.functional as F
class QNetwork(nn.Module):
def __init__(self, state_size, action_size, seed, fc1_units=128, fc2_units=128, fc3_units=128):
super(QNetwork, self).__init__()
self.seed = torch.manual_seed(seed)
self.fc1 = nn.Linear(state_size, fc1_units)
self.dropout1 = nn.Dropout(p=0.6)
self.fc2 = nn.Linear(fc1_units, fc2_units)
self.dropout2 = nn.Dropout(p=0.6)
self.fc3 = nn.Linear(fc2_units, fc3_units)
self.dropout3 = nn.Dropout(p=0.6)
self.fc4 = nn.Linear(fc3_units, action_size)
def forward(self, state):
x = self.fc1(state)
x = self.dropout1(x)
x = F.relu(x)
x = self.fc2(x)
x = self.dropout2(x)
x = F.relu(x)
x = self.fc3(x)
x = self.dropout3(x)
x = F.relu(x)
return self.fc4(x)
from dqn_agent import Agent
agent = Agent(state_size=8, action_size=4, seed=3)
Untrained Agent
The untrained agent is terrible, of course, and immediately crashes (although disappointingly not in a ball of fire).
env = wrappers.Monitor(env, "./gym-results", force=True)
state = env.reset()
for _ in range(1000):
action = agent.act(state)
observation, reward, done, info = env.step(action)
if done: break
env.close()
video = io.open('./gym-results/openaigym.video.%s.video000000.mp4' % env.file_infix, 'r+b').read()
encoded = base64.b64encode(video)
HTML(data='''
<video width="360" height="auto" alt="test" controls><source src="data:video/mp4;base64,{0}" type="video/mp4" /></video>'''
.format(encoded.decode('ascii')))
Train the Agent
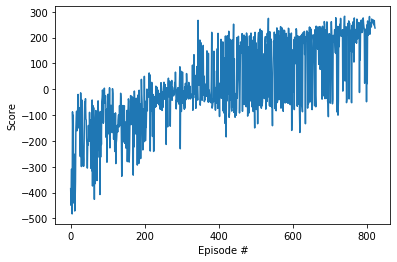
Training proceeds as usual. The environment is considered solved when the average reward over 100 episodes exceeds 200, which was achieved after 723 episodes.
def dqn(n_episodes=2000, max_t=1000, eps_start=1.0, eps_end=0.01, eps_decay=0.995):
scores = [] # list containing scores from each episode
scores_window = deque(maxlen=100) # last 100 scores
eps = eps_start # initialize epsilon
for i_episode in range(1, n_episodes+1):
state = env.reset()
score = 0
for t in range(max_t):
action = agent.act(state, eps)
next_state, reward, done, _ = env.step(action)
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
eps = max(eps_end, eps_decay*eps) # decrease epsilon
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_window)), end="")
if i_episode % 100 == 0:
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_window)))
if np.mean(scores_window)>=200.0:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode-100, np.mean(scores_window)))
torch.save(agent.qnetwork_local.state_dict(), 'checkpoint.pth')
break
return scores
scores = dqn()
# plot the scores
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
Episode 100 Average Score: -177.97
Episode 200 Average Score: -124.90
Episode 300 Average Score: -37.344
Episode 400 Average Score: 15.484
Episode 500 Average Score: 54.92
Episode 600 Average Score: 98.795
Episode 700 Average Score: 120.36
Episode 800 Average Score: 173.05
Episode 823 Average Score: 200.43
Environment solved in 723 episodes! Average Score: 200.43
Watch the Trained Agent
It took a bit of hyperparameter turning, but the trained agent looks like it does a pretty good job!
env = gym.make('LunarLander-v2')
env.seed(3)
env = wrappers.Monitor(env, "./gym-results", force=True)
# load the weights from file
agent.qnetwork_local.load_state_dict(torch.load('checkpoint.pth'))
state = env.reset()
for j in range(1000):
action = agent.act(state)
state, reward, done, _ = env.step(action)
if done: break
env.close()
video = io.open('./gym-results/openaigym.video.%s.video000000.mp4' % env.file_infix, 'r+b').read()
encoded = base64.b64encode(video)
HTML(data='''
<video width="360" height="auto" alt="test" controls><source src="data:video/mp4;base64,{0}" type="video/mp4" /></video>'''
.format(encoded.decode('ascii')))




Comments