
Driving Up A Mountain Faster
Double DQN
The DeepMind researchers developed the Double Deep Q-Network after observing that the DQN target network is prone to overestimating Q-Values.
To fix this, they proposed using the online model instead of the target model when selecting the best actions for the next states, and using the target model only to estimate the Q-Values for these best actions.
First, import the usual stuff.
import gym
import numpy as np
import tensorflow as tf
from tensorflow import keras
from collections import deque
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# To get smooth animations
import matplotlib.animation as animation
mpl.rc('animation', html='jshtml')
try:
import pyvirtualdisplay
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
except ImportError:
pass
It ends up being a minor tweak to the model training function DQN algorithm. The four lines I changed are commented with #DDQN - everything else in the DDQNagent class is unchanged.
class DDQNagent:
def __init__(self, state_size, action_size, episodes):
self.gamma = 0.95
self.batch_size = 64
self.state_size = state_size
self.action_size = action_size
self.episodes = episodes
self.replay_memory = deque(maxlen=2000)
self.optimizer = tf.keras.optimizers.Adam(lr=0.001)
self.loss_fn = keras.losses.Huber()
def build_model(self):
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, activation="relu", input_shape=[self.state_size]),
tf.keras.layers.Dense(32, activation="relu"),
tf.keras.layers.Dense(self.action_size)
])
return model
def add_memory(self, state, action, reward, next_state, done):
self.replay_memory.append((state, action, reward, next_state, done))
def sample_experiences(self):
indices = np.random.randint(len(self.replay_memory), size=self.batch_size)
batch = [self.replay_memory[index] for index in indices]
states, actions, rewards, next_states, dones = [
np.array([experience[field_index] for experience in batch])
for field_index in range(5)]
return states, actions, rewards, next_states, dones
def train_model(self, model):
states, actions, rewards, next_states, dones = self.sample_experiences()
next_Q_values = model.predict(next_states)
best_next_actions = np.argmax(next_Q_values, axis=1) # DDQN
next_mask = tf.one_hot(best_next_actions, self.action_size).numpy() # DDQN
next_best_Q_values = (target.predict(next_states) * next_mask).sum(axis=1) # DDQN
target_Q_values = (rewards + (1 - dones) * self.gamma * next_best_Q_values) # DDQN
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, self.action_size)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)
loss = tf.reduce_mean(self.loss_fn(target_Q_values, Q_values))
grads = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, model.trainable_variables))
The only other change needed is to create the target model by cloning the online model as show in the two lines commented with # DDQN below. That’s it! So now I’ll train the Dueling DQN agent for 2000 episodes and see how its performance compares to DQN.
keras.backend.clear_session()
best_score = 200
episodes = 2000
env = gym.make('MountainCar-v0')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DDQNagent(state_size, action_size, episodes)
model = agent.build_model()
rewards = []
target = keras.models.clone_model(model) # DDQN
target.set_weights(model.get_weights()) # DDQN
for episode in range(episodes):
state = env.reset()
for step in range(200):
epsilon = max(1 - episode/(episodes*0.8), 0.01)
if np.random.rand() < epsilon: action = np.random.randint(action_size)
else: action = np.argmax(model.predict(state[np.newaxis])[0])
next_state, reward, done, info = env.step(action)
if next_state[0] - state[0] > 0 and action == 2: reward = 1
if next_state[0] - state[0] < 0 and action == 0: reward = 1
agent.add_memory(state, action, reward, next_state, done)
state = next_state.copy()
if done:
break
rewards.append(step)
if step < best_score:
best_weights = model.get_weights()
best_score = step
print("\rEpisode: {}, Best Score: {}, eps: {:.3f}".format(episode, best_score, epsilon), end="")
if episode > 50:
agent.train_model(model)
model.set_weights(best_weights)
env.close()
Episode: 51, Best Score: 199, eps: 0.968WARNING:tensorflow:Layer dense is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.
If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.
To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.
Episode: 1999, Best Score: 83, eps: 0.0106
plt.figure(figsize=(8, 4))
plt.plot(rewards)
plt.xlabel("Episode", fontsize=14)
plt.ylabel("Score", fontsize=14)
plt.show()
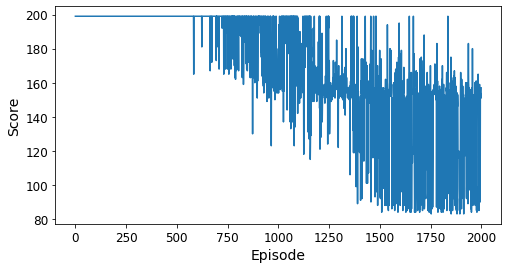
Compared to the DQN, the best score is better (83 here versus 107 for the DQN). It looks less stable, though. Eyeballing things, it looks like the average score over the last 200 epidodes is 125-130-ish, which is better than the 145-ish with DQN. There are a lot of sub-110 scores, thouch, so this has some promise for pursuing the goal of “solving” the environment (100 successive eposodes with 110 or fewer steps).
Dueling Double DQN
I looked for a simple explanation for this additional DeepMind-developed tweak but didn’t find one. The Dueling Double DQN algorithm is an addition to the Double DQN I just trained. The difference between the two algorithms is in how the NN is built, and the changes are entirely in the build_model function below. In short, there are now two separate estimators. There is an estimator for the state value function (state_values below), and there is an estimator for the action advantage function (raw_advantages below). Aurélien Géron again to explain the math:
…note that Q-Value of a state-action pair (s, a) can be expressed as Q(s, a) = V(s) + A(s, a), where V(s) is the value of state s and A(s, a) is the advantage of taking the action a in state s, compared to all other possible actions in that state. Moreover, the value of a state is equal to the Q-Value of the best action a* for that state (since we assume the optimal policy will pick the best action), so V(s) = Q(s, a), which implies that A(s, a) = 0. In a Dueling DQN, the model estimates both the value of the state and the advantage of each possible action. Since the best action should have an advantage of 0, the model subtracts the maximum predicted advantage from all predicted advantages.
Let’s see how this does compared to Double DQN. I’m going to increase the learning rate, too.
class DuelDQNagent:
def __init__(self, state_size, action_size, episodes):
self.gamma = 0.95
self.batch_size = 64
self.state_size = state_size
self.action_size = action_size
self.episodes = episodes
self.replay_memory = deque(maxlen=2000)
self.optimizer = tf.keras.optimizers.Adam(lr=0.02) # increased from 0.001
self.loss_fn = keras.losses.Huber()
def build_model(self): # Dueling Double DQN
K = keras.backend
input_states = keras.layers.Input(shape=[self.state_size])
hidden1 = keras.layers.Dense(32, activation="elu")(input_states)
hidden2 = keras.layers.Dense(32, activation="elu")(hidden1)
state_values = keras.layers.Dense(1)(hidden2) # state value function estimator
raw_advantages = keras.layers.Dense(self.action_size)(hidden2) # action advantage function estimator
advantages = raw_advantages - K.max(raw_advantages, axis=1, keepdims=True)
Q_values = state_values + advantages
model = keras.models.Model(inputs=[input_states], outputs=[Q_values])
return model
def add_memory(self, state, action, reward, next_state, done):
self.replay_memory.append((state, action, reward, next_state, done))
def sample_experiences(self):
indices = np.random.randint(len(self.replay_memory), size=self.batch_size)
batch = [self.replay_memory[index] for index in indices]
states, actions, rewards, next_states, dones = [
np.array([experience[field_index] for experience in batch])
for field_index in range(5)]
return states, actions, rewards, next_states, dones
def train_model(self, model):
states, actions, rewards, next_states, dones = self.sample_experiences()
next_Q_values = model.predict(next_states)
best_next_actions = np.argmax(next_Q_values, axis=1)
next_mask = tf.one_hot(best_next_actions, self.action_size).numpy()
next_best_Q_values = (target.predict(next_states) * next_mask).sum(axis=1)
target_Q_values = (rewards + (1 - dones) * self.gamma * next_best_Q_values)
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, self.action_size)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis=1, keepdims=True)
loss = tf.reduce_mean(self.loss_fn(target_Q_values, Q_values))
grads = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, model.trainable_variables))
Nothing changed in the next code block.
keras.backend.clear_session()
best_score = 200
episodes = 2000
env = gym.make('MountainCar-v0')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DuelDQNagent(state_size, action_size, episodes)
model = agent.build_model()
rewards = []
target = keras.models.clone_model(model)
target.set_weights(model.get_weights())
for episode in range(episodes):
state = env.reset()
for step in range(200):
epsilon = max(1 - episode/(episodes*0.8), 0.01)
if np.random.rand() < epsilon: action = np.random.randint(action_size)
else: action = np.argmax(model.predict(state[np.newaxis])[0])
next_state, reward, done, info = env.step(action)
if next_state[0] - state[0] > 0 and action == 2: reward = 1
if next_state[0] - state[0] < 0 and action == 0: reward = 1
agent.add_memory(state, action, reward, next_state, done)
state = next_state.copy()
if done:
break
rewards.append(step)
if step < best_score:
best_weights = model.get_weights()
best_score = step
print("\rEpisode: {}, Best Score: {}, eps: {:.3f}".format(episode, best_score, epsilon), end="")
if episode > 50:
agent.train_model(model)
model.set_weights(best_weights)
env.close()
Episode: 51, Best Score: 199, eps: 0.968WARNING:tensorflow:Layer dense is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.
If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.
To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.
Episode: 1999, Best Score: 83, eps: 0.0100
plt.figure(figsize=(8, 4))
plt.plot(rewards)
plt.xlabel("Episode", fontsize=14)
plt.ylabel("Score", fontsize=14)
plt.show()
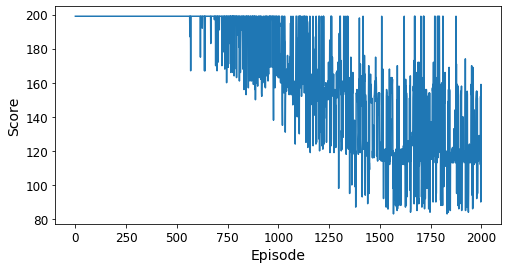
Seems to be a little more stable. Same best score, and maybe a slightly better average score over the last 200 episodes. Still haven’t solved the environment, though. Looks like that’s going to take some work.




Comments