
Ridge Regression Adjusted Statistics
The idea for this post started off as essentially a replication of this post but using R and Tidymodels instead of Python. Once I got that done, I had an idea of making an animated plot instead of the static plot at the end of the post I referenced. I also wanted to get that code worked out because I noticed that a couple of animated images in a tutorial I had written weren’t rendering.
Get the Data
I’m not going to go through all the detail about why I’m going through these steps because, again, it’s just re-creating what was done in the above link. In a nutshell, I’m going to calculate adjusted offense and defense scores for FBS college football teams based on each team’s strength of schedule week by week through the 2021 season.
I’m also not going to go over making API calls because 1) I covered that here, and 2) I’ve already downloaded that data and saved it to disk. You can see the code necessary for the API calls commented out, but really I’m just reading the data from disk that I saved earlier. The first data set games is basic information about each game of the season.
library(httr)
library(tidyjson)
library(tidymodels)
library(tidyr)
# get game info for 2021
# df <-
# httr::GET(
# url = "https://api.collegefootballdata.com/games?year=2021",
# httr::add_headers(
# Authorization = paste("Bearer", Sys.getenv("YOUR_API_TOKEN"))))
#
# games21 <- tibble(data = content(df, "parsed")) %>% unnest_wider(data)
#
# rm(df)
#
# games21 <-
# games21 %>%
# select(id, season, week, neutral_site, home_team, home_conference, home_pregame_elo,
# away_team, away_conference, away_pregame_elo)
#
# saveRDS(games21, "games21.RData")
games <- readRDS("games21.RData")
head(games)
## # A tibble: 6 x 10
## id season week neutral_site home_team home_conference home_pregame_elo
## <int> <int> <int> <lgl> <chr> <chr> <int>
## 1 401282714 2021 1 FALSE Illinois Big Ten 1393
## 2 401286187 2021 1 FALSE Fresno S~ Mountain West 1464
## 3 401309833 2021 1 FALSE UCLA Pac-12 1517
## 4 401282049 2021 1 FALSE New Mexi~ FBS Independen~ 1261
## 5 401310693 2021 1 FALSE San José~ Mountain West NA
## 6 401282050 2021 1 TRUE Jacksonv~ <NA> NA
## # ... with 3 more variables: away_team <chr>, away_conference <chr>,
## # away_pregame_elo <int>
Then I get a dataset that identifies which teams are FBS teams, so I can filter out the games against non-FBS opponents.
# get the ID of non-FBS games
# fbs_teams <-
# httr::GET(
# url = "https://api.collegefootballdata.com/teams/fbs?year=2021",
# httr::add_headers(
# Authorization = paste("Bearer", Sys.getenv("YOUR_API_TOKEN"))))
#
# fbs <-
# tibble(data = content(fbs_teams, "parsed")) %>%
# unnest_wider(data) %>%
# unnest_wider(logos) %>%
# rename("logo" = "...1", "logo2" = "...2") %>%
# select(-location)
#
# saveRDS(fbs, "fbs_teams.RData")
# rm(fbs_teams)
fbs <- readRDS("fbs_teams.RData")
fbsIDs <-
games %>%
filter(home_team %in% (fbs %>% .$school) &
away_team %in% (fbs %>% .$school)) %>% .$id
games <- games %>% filter(id %in% fbsIDs)
The last dataset contains play-by-play statistics for each games. I’m primarily interested in the ppa column, which is the predicted points added of each play and apparently is the same thing as EPA - expected points added. I also do some manipulation to account for home field advantage.
# get PBP data
# for (wk in 1:max(games$week)){
# print(wk)
# df <-
# httr::GET(
# url = paste0("https://api.collegefootballdata.com/plays?year=2021&week=", as.character(wk)),
# httr::add_headers(
# Authorization = paste("Bearer", Sys.getenv("YOUR_API_TOKEN"))))
#
# if (wk == 1){pbp21 <- tibble(data = content(df, "parsed")) %>% unnest_wider(data)}
# else{pbp21 <- pbp21 %>% bind_rows(tibble(data = content(df, "parsed")) %>% unnest_wider(data))}
# }
#
# rm(df, wk)
# saveRDS(pbp21, "pbp21.RData")
pbp21 <- readRDS("pbp21.RData")
pbp21 <-
pbp21 %>%
filter(game_id %in% fbsIDs) %>%
select(game_id, offense, defense, home, ppa) %>%
drop_na() %>%
left_join(games %>% select(id, neutral_site, week), by = c("game_id" = "id")) %>%
mutate(
hfa = case_when(
home == offense ~ 1,
home == defense ~ -1),
hfa = ifelse(neutral_site, 0, hfa)) %>%
select(offense, hfa, defense, ppa, week) %>%
mutate_if(is.character, factor)
pbp21 <- pbp21 %>% mutate(ppa = as.numeric(as.character(ppa)))
head(pbp21)
## # A tibble: 6 x 5
## offense hfa defense ppa week
## <fct> <dbl> <fct> <dbl> <int>
## 1 Alabama 0 Miami -0.296 1
## 2 Alabama 0 Miami -0.559 1
## 3 Alabama 0 Miami 2.18 1
## 4 Alabama 0 Miami 0.995 1
## 5 Alabama 0 Miami 0.575 1
## 6 Alabama 0 Miami 0.136 1
Ridge Regression
This block of code loops over the weeks of the season, tunes and fits a ridge regression model for each week. The regression model for week 1 includes all week 1 play-by-play data, the week 2 model includes week 1 and 2, and so on.
# define the model
lm_mod <-
linear_reg(penalty = tune(), mixture = 0) %>%
set_engine("glmnet")
# hyperparameter tuning grid
lambda_grid <- tibble(penalty = c(0, 10^seq(-2, 2, length.out = 25)))
# loop through the weeks
for (wk in 1:15){
# define the recipe
lm_rec <-
recipe(ppa ~ ., data = pbp21 %>% filter(week <= wk) %>% select(-week)) %>%
step_dummy(all_nominal_predictors(), one_hot = TRUE)
# cread cross-validation folds
folds <- vfold_cv(pbp21 %>% filter(week <= wk) %>% select(-week), v = 5)
# define the workflow
lm_wflow <-
workflow() %>%
add_model(lm_mod) %>%
add_recipe(lm_rec)
# get the tuning results
lm_res <-
lm_wflow %>%
tune_grid(
resamples = folds,
grid = lambda_grid,
control = control_grid(save_pred = TRUE)
)
# get the model with the lowest root mean squared error
lowest_rmse <- lm_res %>% select_best("rmse")
# finalize the workflow with the best model
lm_final_wf <-
lm_wflow %>%
finalize_workflow(lowest_rmse)
# get the final fit
lm_final_fit <-
lm_final_wf %>%
fit(pbp21 %>% filter(week <= wk) %>% select(-week))
# extract the coefficients
adjStats <-
broom::tidy(lm_final_fit) %>%
separate(term, into = c("side", "team"), sep = "_", fill = "left") %>%
select(-penalty)
# separate the intercept and home field advantage coefficients
otherTerms <-
adjStats %>%
slice(1:2) %>%
select(-side)
# get the remaining coefficients
adjStats <-
adjStats %>%
slice(3:nrow(adjStats))
# add the intercept term to the other coefficients
adjStats <-
adjStats %>%
mutate(estimate = estimate + otherTerms %>% filter(team == "(Intercept)") %>% .$estimate)
# fix team name formatting (Oregon.State to Oregon State)
adjStats <-
adjStats %>%
mutate(team = stringr::str_replace_all(team, "\\.", " "))
# make dataframe wider
adjStats <-
adjStats %>%
pivot_wider(names_from = side, values_from = estimate) %>%
rename("adjOff" = "offense", "adjDef" = "defense")
# get the unadjusted (raw) stats - although I don't need this for the plot later
rawOff <-
pbp21 %>% group_by(offense) %>% summarize(meanPPA = mean(ppa)) %>%
rename("team" = "offense", "rawOff" = "meanPPA")
# same thing for raw defense
rawDef <-
pbp21 %>% group_by(defense) %>% summarize(meanPPA = mean(ppa)) %>%
rename("team" = "defense", "rawDef" = "meanPPA")
# bind everything together into one dataframe
if (wk == 1){
df <-
adjStats %>%
left_join(rawOff, by = "team") %>%
left_join(rawDef, by = "team") %>%
mutate(week = wk)}
else{
df_new <-
adjStats %>%
left_join(rawOff, by = "team") %>%
left_join(rawDef, by = "team") %>%
mutate(week = wk)
df <- df %>% bind_rows(df_new)
}
}
head(df)
## # A tibble: 6 x 6
## team adjOff adjDef rawOff rawDef week
## <chr> <dbl> <dbl> <dbl> <dbl> <int>
## 1 Air Force 0.184 0.184 0.272 0.166 1
## 2 Akron 0.186 0.269 0.142 0.460 1
## 3 Alabama 0.208 0.159 0.320 0.0661 1
## 4 Appalachian State 0.208 0.187 0.256 0.0576 1
## 5 Arizona 0.173 0.194 0.0404 0.248 1
## 6 Arizona State 0.184 0.184 0.296 0.127 1
Animated Plot
Now the visualization. I’ll use gganimate to animate the plot and ggimage to render team icons on the plot.
library(gganimate)
library(ggimage)
Performing ridge regression caused a team names to get messed up if they had non alphanumeric characters, so I’ll fix that. There’s also no week 0 to use as a starting point, so to get them roughly centered, I’ll just set them as the mean of week 1 stats. Lastly, I add the links to the team logos.
df <-
df %>% mutate(team = case_when(
team == "Hawai i" ~ "Hawai'i",
team == "Miami OH " ~ "Miami (OH)",
team == "Texas A M" ~ "Texas A&M",
TRUE ~ team
))
# Add a week 0
df <-
tibble(team = fbs$school,
adjOff = df %>% filter(week == 1) %>% .$adjOff %>% mean(),
adjDef = df %>% filter(week == 1) %>% .$adjDef %>% mean(),
rawOff = 0,
rawDef = 0,
week = 0) %>%
bind_rows(df)
# add logos
df <- df %>% left_join(fbs %>% select(school, logo), by = c("team" = "school"))
To generate the plots with team names, I use geom_label(). I then specify how the frame transitions shold work and then generate the plot. This black of code took about two minutes to execute.
# generate the basic plot
p <- ggplot(df, aes(x=adjOff, y=adjDef)) +
geom_label(aes(label=team), fill = df$color, color = df$alt_color, vjust=0.5, hjust=0.5) +
scale_y_reverse() +
xlab("Adjusted Offense") +
ylab("Adjusted Defense") +
theme_bw() +
theme(legend.position="none")
# specify animation details
anim <- p + transition_states(week,
transition_length = 2,
state_length = 2,
wrap = FALSE) +
ease_aes('cubic-in-out') +
ggtitle('Week {closest_state}')
animate(anim, width = 800, height = 800, end_pause = 20, fps = 20, duration = 15)
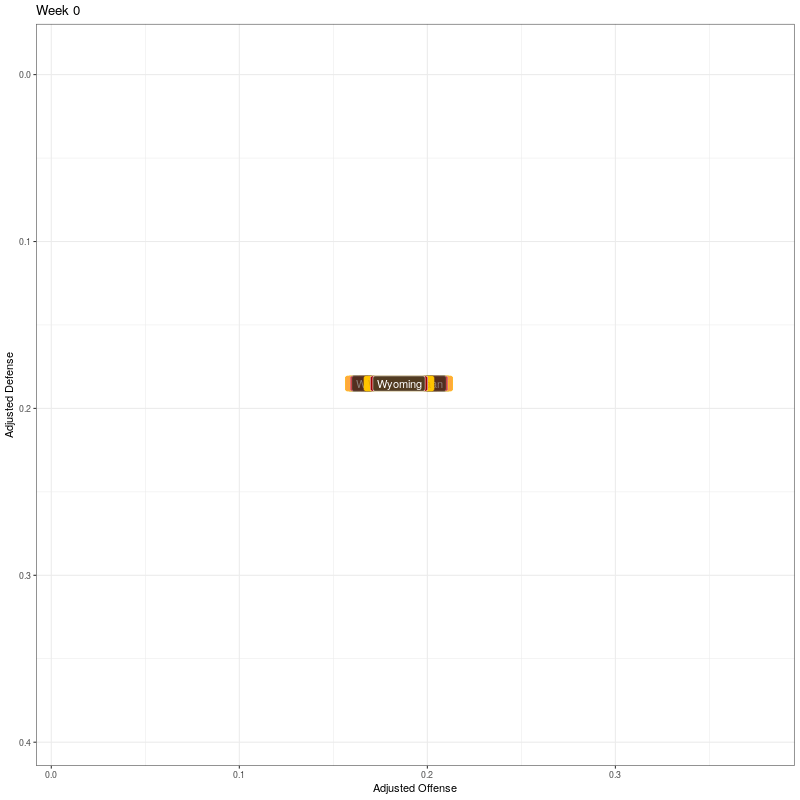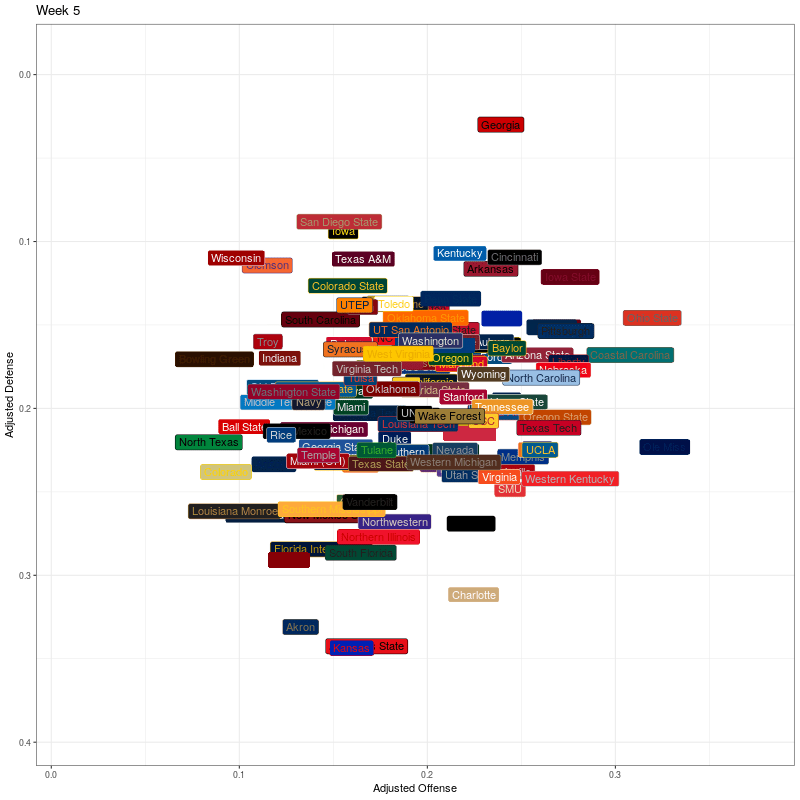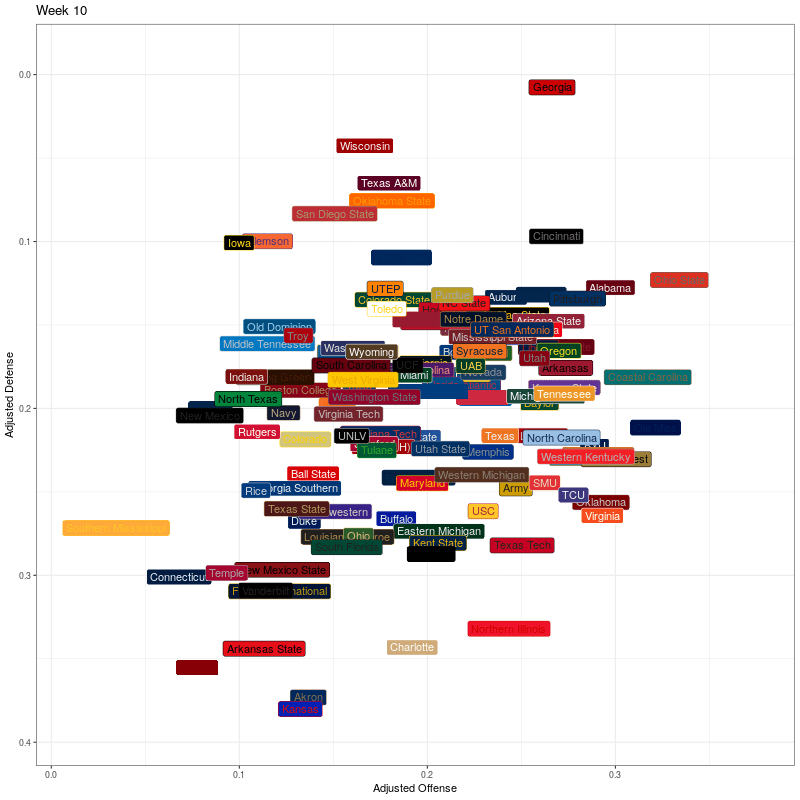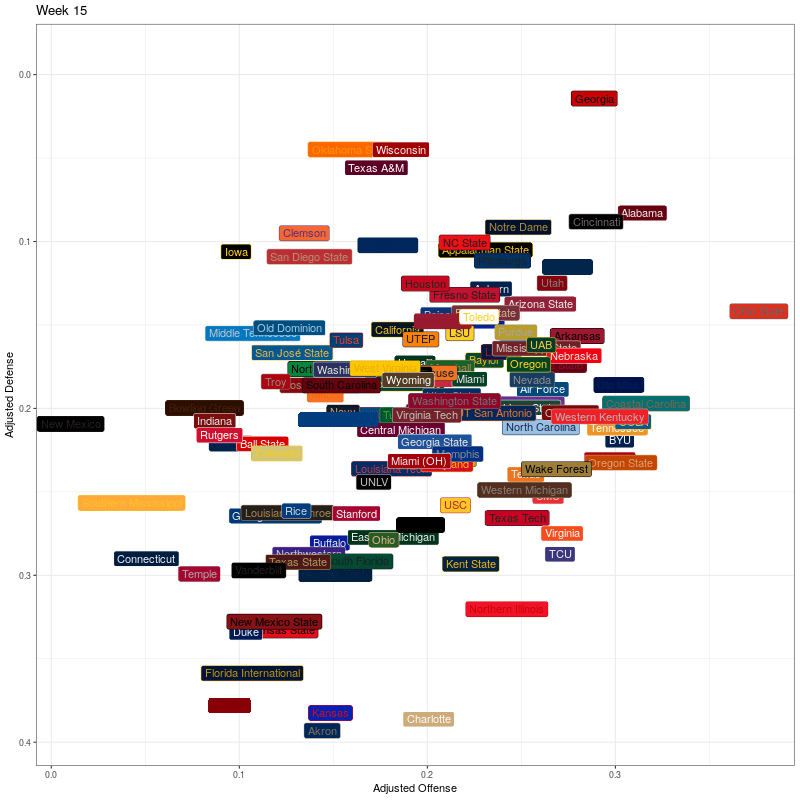
Second, I’ll use team logos instead of text labels. It took an AWS t2.medium EC2 instance about 45 minutes to generate the graphic. One thing that could be improved for efficiency is that the logo column contains urls for the team logos. There are 130 logos and 16 weeks (including week 0), so I’m getting the same 130 logos 16 times when I should only need to get them once. I haven’t worked out how to solve that yet, but for now at least I have something that works.
p2 <- ggplot(df, aes(x=adjOff, y=adjDef)) +
geom_image(aes(image=logo)) +
scale_y_reverse() +
xlab("Adjusted Offense") +
ylab("Adjusted Defense") +
theme_bw() +
theme(legend.position="none")
anim2 <- p2 + transition_states(week,
transition_length = 2,
state_length = 2,
wrap = FALSE) +
ease_aes('cubic-in-out') +
ggtitle('Week {closest_state}')
animate(anim2, width = 800, height = 800, end_pause = 20, fps = 20, duration = 15)
![]()




Comments